Debugging
Things go wrong, so read on.
Usage and limitations of the python debugging tools
By far the most common way to debug the construction of a Node (i.e. the creation of the xxx_worker.py script) and its subsequent use in a pipeline is to use the Python standard debugging tools. That is the Python debugger and the print method. Both those will work just fine as long as the Node’s worker process runs on the same machine that Heron’s GUI is also running. The print method will print to the Heron’s command line window while a debugger will stop the xxx_worker.py script in exactly the same way as if it was called by Python (which it is, just through the com process).
The logging system
If the worker process is running on a different machine then neither the debugger will see it nor any print statements will pass their output to the main machine and Heron’s command line window. In order to solve this (and to also keep a general eye on Heron’s overall performance) Heron has implemented two levels of Python logging. Those can be accessed by the Saving secondary window of each Node.
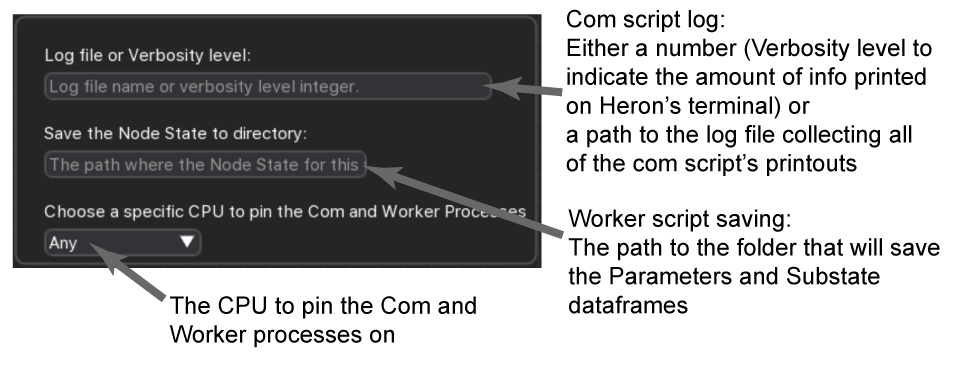
Figure 1
The com process’s verbosity and log
Each Node’s Saving secondary window provides an entry named ‘Log file or Verbosity level’. There a user can set either a number (for now all numbers do the same thing but in the future there might be more verbosity levels) or a full path to a log file.
If there is a number then the com process of the Node will output to Heron’s command line window a detailed description of every message as it leaves the com process. This includes the different times it took for the message to pass through the different processes. For example a Transform com process will output the time it took the message to get from the com process of the upstream Node to the current com process, the time it took to be send to the worker process, be transformed and arrive back at the com process and the time it took to be sent to the downstream Node’s com process.
If the ‘Log file or Verbosity level’ entry gets a path to a log file (xxx/xxx/some_file.log) then the com process will output some basic info to that file every time it processes a message. This info will involve the index of the message in the current Node (i.e. how many messages this Node has processed), the time the com process finishes processing the message and if the message is coming from an upstream Node also the index of the message in that Node and the topic of the message (i.e. the string that tells which Node and which output the message came from and which input the message has arrived into this Node).
Note
These log files are very useful to be able to track messages across Nodes. How they can be used to time match packets across processes is further described in the Synchronisation section.
The global and local log files
Heron offers two other logging systems so that Node developers can log information that is happening on the worker processes of the Nodes they are developing.
The first is the global logging system. By importing Python’s logging package a Node developer can use it’s functions, e.g.:
logging.debug('message)
logging.error('message)
in order to log messages to a Heron.log file that gets automatically generated in the Heron/Heron directory. That file will also log messages from any package that uses logging that is being used in Heron’s functionality (for example one will see a lot of messages there from paramiko as Node sockets connect to the forwarders’ processes sockets).
Another important use of the global Heron/Heron/Heron.log file is that it registers any traces produced when the code breaks and a Node in the pipeline shuts down. So if you see a message in Heron’s command line about a Node killing itself (which is the output of the end of life functionality) then check in the Heron.log file for a trace as to what exactly happened.
Heron automatically produces this global log file on any machine that runs Heron during a pipeline. So a developer can register debugging messages in a worker script of a Node that runs on a different machine to Heron’s GUI. On that machine Heron will generate a Heron.log file and the messages will be registered there. The above point about abnormal termination and stack trace registering applies also to worker processes running on separate machines, so if something goes wrong one should first check the Heron.log file on the machine that the worker process of the Node is running.
Heron also offers a local way to log information. In the general_utilities there is a function called setup_logger. Using this will generate a separate logger with a specified log file that the worker script of a Node can use to log information. Use this as follows:
from Heron import general_utils as gu
logger = gu.setup_logger('Name of Logger', full_path_log_file_name)
logger.info('Some information')
logger.debug('Maybe we should look into that')
logger.error('Aarghh, something is wrong')
Of course if the worker script is meant to run on a different machine the full_path_log_file_name must make sense for the machine that it runs on since the logger is not designed to pass its messages to different machines.
The substate and parameters saving system
Apart from the logging capabilities of Heron itself and of the com process of each Node, Heron allows the worker process of each Node to save information at every loop step (for the Sources case) or every time it gets called (for the Transform and Sink cases). This capability is fully described in the The Saving State System section.
Hanging processes
When Heron crashes all processes should receive a kill command and stop themselves after HEARTBEAT_RATE * HEARTBEATS_TO_DEATH seconds (these variables are defined in the constants.py file). The same goes for a process that crashed because there was a bug in its code. If the error itself doesn’t kill the process but makes it unresponsive then it will kill itself after the above specified amount of time.
Yet, sometimes, some process do not kill themselves. This happens very rarely but it is possible. When that happens, restarting the Graph (even from a new Heron GUI) will throw an error claiming that the sockets required for communication are not available. The only way to stop such a process is to access it and kill it manually in whatever the OS provides. For example in Windows this can be done from TaskManager while from Linux with the top command.